Raven hardware details
This page summarizes additional details on the Raven hardware and presents performance measurements from microbenchmarks.
Node architecture
The Raven system comprises of compute nodes powered by dual Intel Xeon IceLake-SP processors (Platinum 8360Y) with 36 physical CPU cores per socket (i.e. 72 per node). These nodes feature 256 GB of RAM, with 64 nodes having 512 GB and 4 nodes featuring 2048 GB. Additionally, there are 192 GPU-accelerated compute nodes, each equipped with 4 Nvidia A100 40GB-SXM GPUs connected via NVLINK3 and connected to the host via PCIe. These GPU nodes also feature 512 GB RAM and use the same Intel Xeon IceLake-SP CPUs.
The CPU nodes are interconnected with a Mellanox HDR InfiniBand network at 100 Gbit/s, whereas the GPU nodes are linked at a rate of 200 Gbit/s.
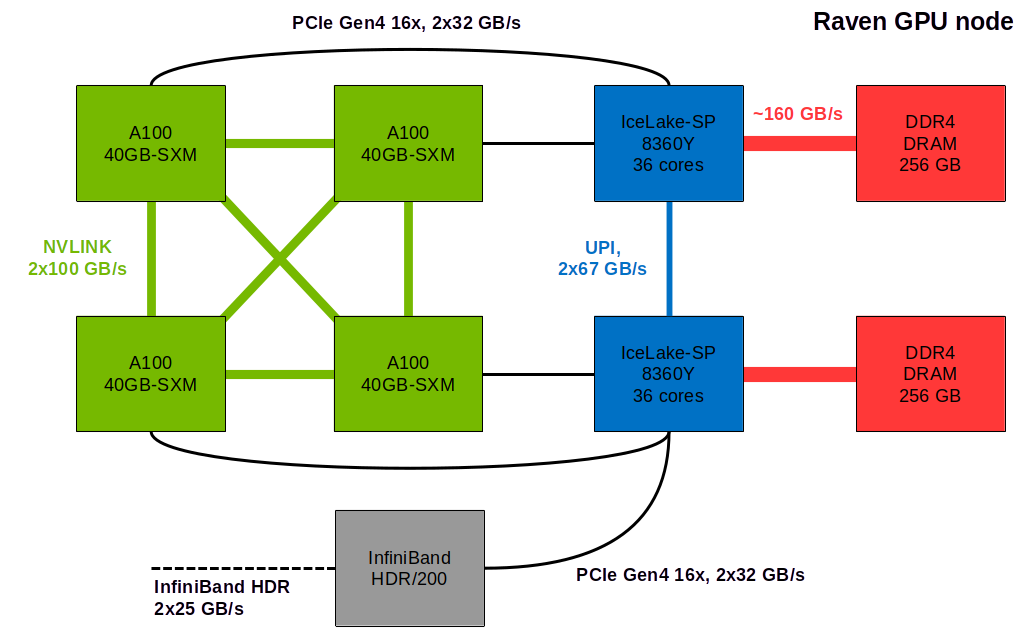
The nominal bandwidths between the components on a Raven GPU node are approximately:
100 GB/s per direction between each of the four A100 GPUs using NVLINK3
67 GB/s per direction between the two CPU sockets using UPI
32 GB/s per direction between each A100 GPU and the host using PCIe4 x16
25 GB/s per direction via the InfiniBand network interface
The following schematic highlights the topology of a Raven GPU node (where the notation ‘2x X GB/s’ refers to full duplex, enabling a bandwidth of X GB/s in each direction simultaneously):
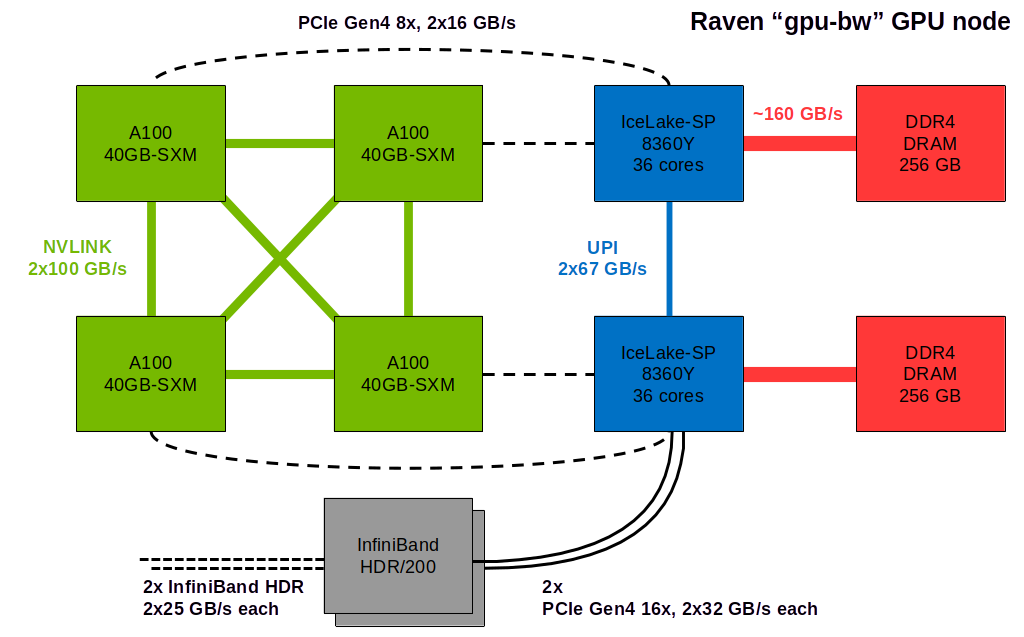
A set of 32 Raven GPU nodes is equipped with a second InfiniBand interface
that doubles the bandwidth into the network to 50 GB/s per direction. On
Slurm, these nodes can be selected via the --constraint="gpu-bw" flag of
sbatch. Due to a limited number of available PCIe lanes, the GPUs on these
nodes are connected to the host at half the bandwidth compared to the regular
Raven GPU nodes. The following schematic show the topology of a Raven
GPU node from the ‘gpu-bw’ type:
Empirical Roofline Models
Below, empirical roofline plots are presented that are based on measurements made on a CPU node and on an individual GPU of Raven. Roofline models illustrate the limitations of a computational kernel due to either the memory bandwidth or the maximum floating point performance of the hardware, depending on the arithmetic intensity of that kernel.


Performance measurements using microbenchmarks
The likwid suite implements a set of microbenchmarks to measure, e.g., the flops and the memory bandwidth a system may achieve. The numbers below are based on actual measurements on a full node, i.e. utilizing all CPU cores and memory channels.
For the measurements on the GPU the BabelStream microbenchmarks were used.
CPU
Currently Loaded Modulefiles:
1) intel/21.6.0
2) likwid/5.2(default)
Flops
instruction set GFlops/s
----------------- ----------
scalar 304.660
SSE 640.023
AVX 1357.607
AVX-FMA 2716.209
AVX512 2685.938
AVX512-FMA 5370.171
Memory Bandwidth
load
instruction set GBytes/s
----------------- ----------
scalar 321.435
SSE 336.826
AVX 338.035
copy
instruction set GBytes/s
----------------- ----------
scalar 260.375
SSE 290.084
AVX 294.560
stream
instruction set GBytes/s
----------------- ----------
scalar 300.476
SSE 303.429
AVX 303.799
triad
instruction set GBytes/s
----------------- ----------
scalar 306.859
SSE 307.839
AVX 307.724
To complement the previously presented numbers, the following plot shows measurements of the memory bandwidth under variation of the number of threads. Each thread is bound (”pinned”) to an individual physical core.
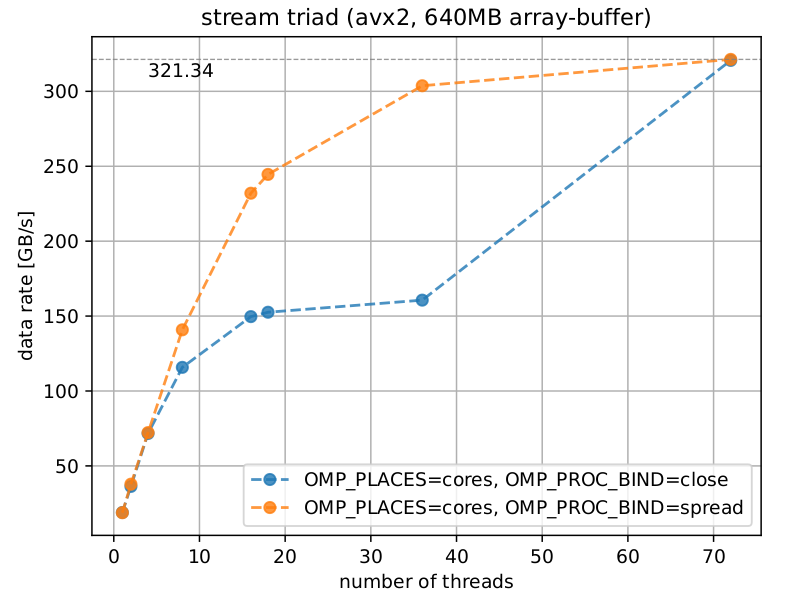
The orange curve depicts measured results based on a scattered pinning, i.e., threads are pinned to physical cores on the two CPU sockets in a round-robin fashion, thereby making use of all available memory channels in a balanced way. As a rule of thumb and evident from the plot, at least half of the physical cores per socket are required to make efficient use of the available memory bandwidth.
In contrast, the blue curve shows results based on a compact pinning, i.e., threads are pinned to the first socket until it is fully occupied (36) before the second socket is populated with threads as well (72). That transition illustrates the memory bandwidth a single socket is able to deliver.
GPU
BabelStream
Version: 4.0
Implementation: CUDA
Running kernels 100 times
Precision: double
Array size: 268.4 MB (=0.3 GB)
Total size: 805.3 MB (=0.8 GB)
Using CUDA device NVIDIA A100-SXM4-40GB
Driver: 11040
Function MBytes/sec Min (sec) Max Average
Copy 1403896.061 0.00038 0.00039 0.00038
Mul 1360548.080 0.00039 0.00040 0.00040
Add 1357798.755 0.00059 0.00060 0.00060
Triad 1362270.774 0.00059 0.00069 0.00060
Dot 1229347.744 0.00044 0.00045 0.00044