
No.221, April 2026
Contents
High-performance Computing
Resource limits at login nodes of the HPC-Systems
In order to maintain the responsiveness of the login nodes on the HPC machines, per-user resource limits were introduced on Raven and also on Viper in late 2024. Over time, even stricter limits had to be enforced, actually.
The following table summarizes the current limits.
| raven[01-02]i | raven[03-04]i | viper[01-02]i | viper[03-06]i | viper[11-12]i | viper13i | |
|---|---|---|---|---|---|---|
| cores | 2 | 6 | 2 | 6 | 2 | 6 |
| memory | 50 GB | 100 GB | 50 GB | 100 GB | 50 GB | 100 GB |
| tasks | 768 | 1536 | 768 | 1536 | 768 | 1536 |
As a consequence, especially because of the limitation of tasks (which actually is the sum of Unix processes and threads per user), some programmes might fail with
fork: retry: Resource temporarily unavailable
In such cases, please double check your process list for stale sessions that might have not terminated properly (ps auxH), and clean those up using standard tools like kill.
Furthermore, we’d encourage users to explicitly choose a login node based on the above table, and no longer rely on our legacy DNS aliases
raven or raven-i (likewise for viper). These legacy aliases will be withdrawn in late 2026.
In case you require more powerful interactive sessions to analyze data on Raven and Viper, we strongly recommend to use our RVS service at Raven and Robin. The latter meanwhile has access to the filesystems /raven/ptmp, /viper/ptmp1 (Viper-CPU), /viper/ptmp2 (Viper-GPU) and /nexus/posix0.
For further insights on potential impacts on parallel builds and GitLab CI jobs on the login nodes, please also refer to our initial article on this topic in issue 217 of Bits&Bytes (December 2024).
Christian Guggenberger
Software News
AMD software
Version 7.2.1 of the ROCm software stack has been installed on Viper-GPU. The
corresponding module is called rocm/7.2.
On Viper-CPU, a new OpenMPI module has been installed for the AOCC compiler.
Users can now compile Fortran codes with MPI using AOCC Flang by loading the
modules aocc/5.1 openmpi/5.0. The MPI wrapper scripts follow the standard
naming scheme, that is, mpif90 for Fortran. Also modules providing HDF5 and
NetCDF are available for this software stack: hdf5-mpi/1.14.1 and
netcdf-mpi/4.9.2.
Tobias Melson
Nvidia HPC SDK
A new module nvhpcsdk/26 has been started with the Nvidia HPC SDK 26.1. Minor version
updates will follow during the year without changing the module name. Update to 26.3 has already been done.
The previous nvhpcsdk/25 is now frozen on version 25.11.
Be aware that the only CUDA version installed with nvhpcsdk/26 is CUDA 13.1. It can be explicitly loaded
with the module cuda/13.1-nvhpcsdk_26 to set the CUDA relevant paths. With the change to CUDA 13+, some
deprecations and API changes have been done. For further details, refer to the CUDA 13 release notes.
Tilman Dannert
New ELPA version 2026.02
The latest ELPA eigensolver library release (version 2026.02.001) brings further performance improvements for GPU-based computations. In particular, ELPA 1-stage GPU tridiagonalization and backtransformation are now both ~10% faster, which leads to overall ~10% speedup for the standard eigenproblems.
As announced in the previous issue 220 of Bits&Bytes, the bugfix number is now dropped from the ELPA module name.
For example, the new release is available as module load elpa/mpi/standard/gpu/2026.02.
In addition, the 2025.06.001 module has received a bugfix update, adding support for multi-architecture Nvidia GPU builds and fixing a bug in the tridiagonal solver.
This and all previous versions are still available with their full version numbers, e.g., module load elpa/mpi/standard/gpu/2025.06.001.
All available ELPA modules can be queried with find-module elpa.
Petr Karpov, Tobias Melson, Andreas Marek
Fortran support added to structured diff and merge tools via incremental parsing

Difftastic and Mergiraf are syntax-aware diff and merge tools that operate on concrete syntax trees instead of raw text. Difftastic computes structural diffs by parsing source code with Tree-sitter, an incremental parsing library that generates concrete syntax trees for many programming languages. Mergiraf builds on the same Tree-sitter infrastructure to perform structured, language-aware merges with improved conflict resolution. Tree-sitter provides fast, error-tolerant parsers and a uniform AST interface, enabling both tools to reason about code structure rather than line-based changes. Therefore the tools can align changes based on actual language structure (functions, expressions, blocks) rather than lines chosen by complicated algorithms, making diffs far more accurate and readable as shown in the screenshot in Figure 1 of Difftastic displaying differences between two Fortran files. Changes are displayed side-by-side by default, because they are no longer line-based. Note how changes are resolved almost to character level and embellished with basic syntax highlighting in bold and italic.
This structure awareness also enables smarter merges that reduce spurious conflicts and preserve intent, unlike traditional line-based tools that often misinterpret reformatting or code movement as substantive changes. Difftastic and Mergiraf can be used directly in Git as diff and merge drivers, respectively.
Recently, Fortran language support has been added by MPCDF to both Difftastic^1 and Mergiraf^2 on their respective development branches via a Tree-sitter Fortran grammar.
Henri Menke
DataShare: Public link passwords
Since the migration of the DataShare service to Nextcloud last year, creating password protected public link has been a two step process: Initially the share is created without a password, which must then be set if desired in the Customize link dialog (see Figure 2).
If there is an issue with saving the password - for example because it doesn’t meet the password strength requirements - the displayed error can easily be overlooked and may lead to the share remaining without a password set at all.
For this reason, new link shares will now always be created with a secure random password by default. The password can still be changed or removed if needed.
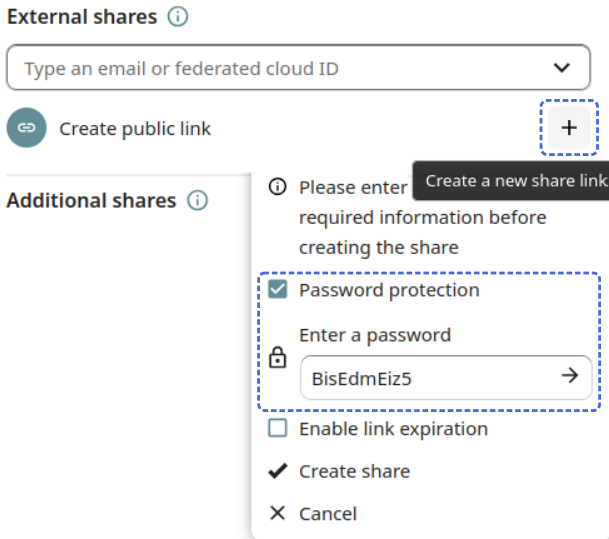
Florian Kaiser
News & Events
AMD workshop
Coming up soon, MPCDF will run another AMD GPU workshop with a focus on the MI300A technology in Viper-GPU. This time, the workshop is split into two parts: A first part in collaboration with HLRS (they also have AMD MI300A APUs in their Hunter system) with four half-day sessions of lectures and exercises in the afternoons of April 21st to 24th, 2026, and a second part with a hackathon on Viper-GPU from April 27th to 29th. The online lectures of the first part will be given by AMD, and the accompanying exercises will be done on AMD cloud resources. The detailed program and the registration link can be found on the HLRS website AMD Instinct GPU Training.
For the online hackathon on the MPCDF Viper-GPU system the week after, users are invited to apply with their code to bring in and to work on profiling and optimization aspects or specific porting issues, supported by experts from AMD and MPCDF. Participants are expected to have a good understanding of their code and they should also be familiar with the relevant parts of the lectures of the previous week, as there will be no introductory lectures for the week of the hackathon. Registration for this event has to be done separately at MPCDF AMD GPU Hackathon.
Tilman Dannert
Introduction to MPCDF Services
The next session of our introductory online course, which is designed to familiarize new users with the MPCDF compute and data services, will be held on April 30th, 2026, 14:00-16:30, online. No registration is necessary, you can just join with the link published on our website. The link is only active at the time of the workshop.
Tilman Dannert
IT4Science Days 2026
Save-the-date: This year’s IT4Science Days - including the “MPG DV-Treffen” - will take place from September 29th to October 1st at the MPG Faßberg campus in Göttingen. Further information as well as registration will become available through the website of the conference. As usual, the “IT-Verantwortlichen Treffen” will start the day before (Monday, September 28). For reference, see also last year’s meeting site.
Raphael Ritz
RDA Deutschland Tagung 2026
The Research Data Alliance Germany had its yearly conference again at the “Geoforschungszentrum (GFZ)” in Potsdam February 24th-25th, 2026. Focus topics were the forthcoming “Forschungsdatengesetz” as well as the future of the National Research Data Infrastructure (NFDI). Further information including slides from most of the contributions are available from the conference website. As in previous years, MPCDF helped to organize the event and contributed to the programm.
Raphael Ritz